Pipelines multi-projets
Anatomie des pipelines
Nous allons nous pencher sur ce qu'est un pipeline.
Vous l'aurez probablement remarqué un pipeline est composé de stages et les stages sont composés de jobs.
Pour rappel: un job consiste à effectuer une ou plusieurs tâches et ce job se retrouve dans un stage.
Mais connaissez-vous les règles pour l'organisation entre les jobs ?
Dans Gitlab, les stages sont exécutés en séquence et les jobs sont exécutés en parallèle dans un stage.
Prenons un exemple:
stages:
- build
- test
- deploy
default:
image: alpine
build_a:
stage: build
script:
- echo "This job builds something."
build_b:
stage: build
script:
- echo "This job builds something else."
test_a:
stage: test
script:
- echo "This job tests something. It will only run when all jobs in the"
- echo "build stage are complete."
test_b:
stage: test
script:
- echo "This job tests something else. It will only run when all jobs in the"
- echo "build stage are complete too. It will start at about the same time as test_a."
deploy_a:
stage: deploy
script:
- echo "This job deploys something. It will only run when all jobs in the"
- echo "test stage complete."
environment: production
deploy_b:
stage: deploy
script:
- echo "This job deploys something else. It will only run when all jobs in the"
- echo "test stage complete. It will start at about the same time as deploy_a."
environment: production
Ce qui se traduit par ce schéma:

Dans cet exemple, vous avons 3 stages qui ont chacun deux jobs.
Au départ, le stage build commence.
Donc, les deux jobs build_a et build_b se réalisent en même temps.
Une fois les jobs terminés, le stage build est terminé et le stage test peut alors commencer.
Ce processus se répètera jusqu'au dernier stage.
Il s'agit d'une approche simple qui ne demande aucune configuration.
Le problème est qu'elle n'est pas optimale.
On se rend vite compte que cette architecture n'est pas la plus rapide.
Pourquoi test_a devrait attendre que build_a et build_b finissent alors que test_a ne dépend que de build_a ?
On va donc essayer d'améliorer les performances de notre pipeline en décrivant les dépendances de nos jobs. N'oubliez pas: "Le temps, c'est de l'argent !"

Pipelines avec dépendances
Reprenons l'exemple précédent.
Nous voulons que la structure suivante pour a: build_a -> test_a -> deploy_a et pareil pour b.
Gitlab nous propose d'ajouter un mot clé needs pour notre job.
Ce mot clé prend une liste de dépendances et Gitlab s'occupera du reste !
stages:
- build
- test
- deploy
default:
image: alpine
build_a:
stage: build
script:
- echo "This job builds something quickly."
build_b:
stage: build
script:
- echo "This job builds something else slowly."
test_a:
stage: test
needs: [build_a]
script:
- echo "This test job will start as soon as build_a finishes."
- echo "It will not wait for build_b, or other jobs in the build stage, to finish."
test_b:
stage: test
needs: [build_b]
script:
- echo "This test job will start as soon as build_b finishes."
- echo "It will not wait for other jobs in the build stage to finish."
deploy_a:
stage: deploy
needs: [test_a]
script:
- echo "Since build_a and test_a run quickly, this deploy job can run much earlier."
- echo "It does not need to wait for build_b or test_b."
environment: production
deploy_b:
stage: deploy
needs: [test_b]
script:
- echo "Since build_b and test_b run slowly, this deploy job will run much later."
environment: production
Ce qui se traduit par ce schéma:

Parfait ! Maintenant, nous avons optimisé notre pipeline. En décrivant les dépendances, nous avons limité les contraintes pour démarrer certains de nos jobs.
Pouvons-nous faire mieux ? Oui ! Dans la prochaine partie, nous allons commencer à travailler sur l'accélération des jobs qui constituent notre pipeline.
Cache
Le principe d'un cache est simple: on consulte un cache en lui donnant une clé.
- S'il connait la clé, alors il nous renvoie la valeur associée.
- Dans le cas contraire, il peut stocker cette valeur pour une consultation ultérieure.
Présentez ainsi, le cache n'a pas l'air d'être si important. Mais ne vous y trompez pas ! Si le calcul de la réponse demande beaucoup de temps, vous pourrez éviter de recalculer la valeur et gagner de précieuses secondes !
Si vous avez déjà fait du développement, le cache est un sujet très important, car il s'agit d'un outil extrêmement puissant !
Dans notre cas, il existe des parties que l'on souhaiterait mettre en cache.
Souvenez-vous des laboratoires précédents, nous avions besoin d'installer les modules de notre projet.
Voici une opération assez lente par rapport au reste des tâches effectuées (test, lint, etc.).
L'idéal serait d'installer les modules une seule fois et ensuite de partager les modules entre nos jobs.
Une seule installation pour tous les contrôler les jobs !
Nous avons vu que NodeJS utilise un package manager appelé NPM pour charger les dépendances d'un projet. Mais il n'est pas le seul à en utiliser un ! Par exemple:
- Python et pip
- Java et Maven
- PHP et Composer
- Ruby et RubyGems
- Rust et Cargo
- Golang et Go
- ... La liste est potentiellement infinie (certains langages ont même plusieurs managers (par exemple Yarn pour NodeJS)).
Gitlab vous propose de créer un ou plusieurs caches pour vos jobs avec une gestion du comportement de ce dernier. Il est par exemple possible d'indiquer qu'un job peut:
- push uniquement: c'est-à-dire qu'une fois fini, le job va envoyer les fichiers désirés dans le cache.
- pull uniquement: c'est-à-dire qu'avant de commencer, le job va récupérer les fichiers du cache.
- push/pull (défaut): c'est-à-dire qu'avant de commencer, le job va récupérer les fichiers du cache ET à la fin le job va envoyer les fichiers désirés dans le cache
Exercice 1: cache des modules
C'est l'heure du duel de l'exercice !
Dans les laboratoires précédents, nous avons conçu un pipeline fonctionnel, mais clairement mal optimisé !
Il est temps d'améliorer le temps d'exécution en faisant deux choses:
- mettre en place un pipeline en décrivant les dépendances de nos jobs.
- mettre en place un cache pour accélérer nos jobs !
Vous savez ce qu'il vous reste à faire.
Vous devez créer un nouveau repository et remettez-y les fichiers du laboratoire précédent.
Vous savez que pour cet exercice, vous ne devez manipuler que le fichier .gitlab-ci.yml.
Pour le cache:
- N'hésitez pas à consulter la documentation !
- Pensez également au comportement désiré de votre cache pour les jobs.
Une fois terminé, vous devriez avoir un pipeline qui fonctionne à plein régime !

Interruption des pipelines
Un détail que vous aurez peut-être noté: nos pipelines ne s'arrêtent pas suite à un nouveau commit. Si un deuxième pipeline est créé pendant qu'un premier pipeline est en cours de réalisation, le deuxième attend que le premier finisse. Ne pourrait-on pas faire mieux ? Cela entraine en effet deux problèmes:
- Le deuxième pipeline doit attendre que le premier finisse. Ce qui fait que ce dernier prend plus de temps qu'il ne devrait.
- Le premier pipeline fonctionne avec un commit qui est déjà dépassé.
Il est donc possible d'indiquer le comportement par défaut des pipelines et des jobs !
Pour définir si un pipeline peut être interrompu, il suffit de définir le auto_cancel du workflow sur:
conservative(défaut): Le pipeline peut être interrompu uniquement si aucun job "non-interruptible" n'a commencé (par défaut, un job est "non-interruptible")interruptible: Le pipeline arrête/supprimer tous les jobs "interruptibles" sans tenir compte des jobs "non-interruptibles" déjà éxécutés.none: Les jobs ne peuvent pas être interrompus.
Maintenant, il est possible de définir si un job est interruptible ou non en mettant:
interruptible: false(défaut)interruptible: true
Prenons deux exemples de la documentation pour bien comprendre.
workflow:
auto_cancel:
on_new_commit: conservative # the default behavior
stages:
- stage1
- stage2
- stage3
step-1:
stage: stage1
script:
- echo "Can be canceled."
interruptible: true
step-2:
stage: stage2
script:
- echo "Can not be canceled."
step-3:
stage: stage3
script:
- echo "Because step-2 can not be canceled, this step can never be canceled, even though it's set as interruptible."
interruptible: true
Que se passe-t-il si un nouveau commit est réalisé ?
Notre pipeline est en mode conservative.
Donc si un seul job interruptible: false a commencé, alors le pipeline ne sera PAS annulé.
Dans le cas contraire, aucun problème.
Donc si step-1 est réalisé, mais pas step-2, alors le pipeline pourra être interrompu.
Dès que step-2 a commencé, le pipeline ne peut plus être arrêté.
Deuxième exemple:
workflow:
auto_cancel:
on_new_commit: interruptible
stages:
- stage1
- stage2
- stage3
step-1:
stage: stage1
script:
- echo "Can be canceled."
interruptible: true
step-2:
stage: stage2
script:
- echo "Can not be canceled."
step-3:
stage: stage3
script:
- echo "Can be canceled."
interruptible: true
Que se passe-t-il si un nouveau commit est réalisé ?
Notre pipeline est en mode interruptible.
Donc si un job interruptible: true est en cours, il est annulé.
S'il n'est pas en cours de réalisation, alors il ne sera pas éxécuté.
Changer le comportement par défaut
Il est possible de changer le comportement par défaut d'un job en jouant sur la propriété default.
En indiquant interruptible: true, par défaut TOUS les jobs deviennent interruptibles.
Mais est-ce une bonne idée ?

Vous devez savoir que tous les jobs ne sont pas si facilement arrêtables. Effectivement si nous lançons une batterie de tests, nous pouvons nous arrêter au milieu. Par contre, pour un déploiement, c'est une terrible idée ! Imaginez, pendant le déploiement votre job coupe l'ancien service pour le remplacer par le nouveau. Sauf que le job est interrompu durant le remplacement... Vous vous retrouvez sans service !
Retenez cette règle: il vaut mieux un pipeline lent mais fonctionnel, plutôt qu'un pipeline rapide mais qui posera un problème. Pour rappel, l'interruption de pipeline n'est qu'une optimisation ! Si vos pipelines sont corrects, vous aurez la possibilité de les optimiser par la suite.
"Pipeline-ception" (pipeline multi-projets)
Nous allons pouvoir attaquer le gros morceau ! Pour l'instant, nous avons un pipeline par projet. Mais parfois, nous avons un projet qui a besoin d'un autre projet. Ce n'est pas quelque chose de si rare dans le monde du développement actuel. Par exemple: si on regarde ce qui se fait sur le web, on voit souvent une architecture API/SPA. Vous savez ce qu'est une API grâce aux laboratoires 2 et 3. Une SPA est une sorte d'interface dynamique et humainement utilisable qui va pouvoir communiquer avec l'API. Dans ce cas, on a bien un projet (SPA) qui dépend d'un autre (API).
On voudra donc peut-être tester l'ensemble de notre système avec des tests end-to-end avec Cypress pour s'assurer que notre SPA se comporte comme attendu avec notre API. Cependant, avant de lancer des tests end-to-end qui sont parfois assez lents, on aimerait s'assurer que le projet API soit correct. Après tout, si l'API ne répond pas ou incorrectement, notre interface ne pourra pas s'adapter correctement et donc les tests end-to-end vont échouer.
Il faudrait donc pouvoir lancer le pipeline du projet API, attendre les résultats et, s'ils sont bons, lancer nos tests end-to-end.
Pour pouvoir réaliser cette série d'actions, nous allons avoir besoin des triggers.
Un trigger (déclencheur en français) va lancer un pipeline d'un projet.
Un trigger sera un job qui va enclencher un autre pipeline.
Définitions des termes que nous allons utiliser par la suite:
- un trigger: un job qui va enclencher un autre pipeline
- un pipeline upstream: il s'agit du pipeline qui contient le trigger et qui va donc créer un autre pipeline
- un pipeline downstream: il s'agit d'un pipeline qui a été créé par autre pipeline
Exemple:
trigger_job:
trigger:
include:
- local: path/to/child-pipeline.yml
Dans ce cas, le trigger va demander à Gitlab de créer un autre pipeline en se basant sur le fichier .yml fourni.
C'est un cas qui peut être intéressant si l'on souhaite utiliser une configuration spéciale pour notre pipeline downtream.
Voici un autre exemple utilisant un autre projet:
trigger_job:
trigger:
project: project-group/my-downstream-project
Ici, le pipeline upstream va demander à Gitlab de récupérer la configuration d'un autre projet pour le pipeline downstream.
Vous devez vous poser la question de l'accès à votre second projet depuis le premier ! Accès via HTTPS ou SSH ? Comment faire si vos projets sont privés ?
Dans notre cas, nous allons opter pour du HTTPS et des projets privés (mais dans un même groupe).
Il existe différentes stratégies pour le comportement du trigger:
- Celui par défaut (quand on ne précise rien): quand le pipeline downstream est créé, le trigger est considéré comme terminé
- Si on indique
strategy: mirror: le trigger est considéré comme terminé quand le pipeline downstream est terminé.
Dans notre mission, nous savons que nous aurons besoin de la deuxième option, car nous souhaitons d'abord lancer les tests unitaires de notre API pour ensuite lancer les tests end-to-end. Avec ce second comportement, il devient dès lors possible d'avoir le comportement attendu.
Exercice 2: "the big one"
Comme expliqué, nous allons mettre en place un gros projet pour cet exercice. Nous aurons trois repository Git:
- Un pour le backend
- Un pour le frontend
- Un qui regroupe les autres (git submodule)
Un backend est la partie "serveur" d'un projet. Il s'agit de la partie du projet qui fonctionne sur les serveurs de l'entreprise. Dans notre cas, il s'agira d'une API.
Un frontend est la partie utilisée par le client. C'est la partie "interface" du projet qui permet d'interagir simplement avec la partie serveur. Dans notre cas, il s'agira d'une interface web.
Un git module est simplement une référence à un autre repository git dans un repository. Dans notre cas, le troisième repository contiendra deux références: une vers le projet backend et l'autre vers le projet frontend
Phase d'initialisation 1
Nous allons créer un groupe qui contiendra nos 3 repository.
En effet, nous voulons que le repository global puisse facilement accéder aux 2 autres repository.
Pour ce faire, il faut se rendre sur la partie "Groups" dans le menu de gauche.
Une fois créé, vous pouvez aller à l'intérieur de ce groupe et vous allez créer les 3 projets suivants: global, back et front.
Dans chaque répertoire, nous allons configurer le 'timeout' maximum des pipelines.
Dans le menu de gauche, allez dans Settings, puis CICD, puis dans General pipelines et dans la partie Timeout mettez la valeur à 10m.
Pour les projets back et front, nous allons autoriser le projet global d'accéder à ces derniers.
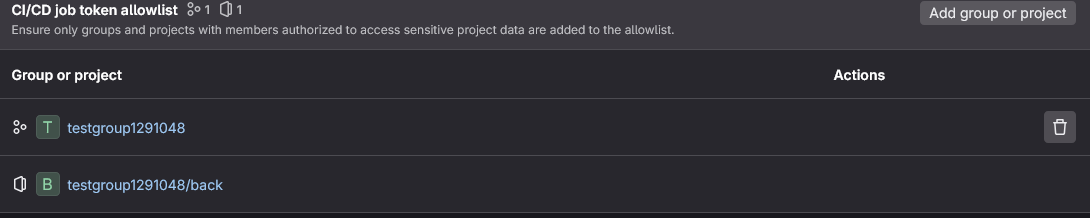
Toujours dans la partie Setting > CICD, dans Job token permissions, ajoutez le groupe.
Tous les projets de ce groupe pourront accéder à ce repository.
Nous aurions pu affiner en mettant le projet, mais nous allons faire simple.
Le repository est lui-même dans la liste. Vous pouvez donc facilement connaitre l'identifiant du groupe. Exemples:

Phase d'initialisation 2
Les repositories étant prêts, nous allons pouvoir ajouter le code dans nos répertoires. Téléchargez le code >> ici <<. Vous avez l'ensemble des fichiers que vous devrez utiliser, mais certains sont incomplets ! Ce sera à vous de les compléter durant l'exercice (section suivante) !
Décompressez le fichier zip, notez la structure: un dossier back, un dossier front et le reste qui est constitué de fichiers et de dossiers.
Vous l'aurez surement compris, nous allons faire correspondre les dossiers back et front à nos répertoires fraichement créés.
Malheureusement, la technique est un peu plus complexe et nous aurons besoin du terminal pour faire ce que nous désirons.
Ouvrez le dossier global (celui qui contient les dossiers back et front) dans VSCode (File > Open Folder).
Vous devriez avoir ceci (la couleur des dossiers pourrait être différente pour vous):
Ensuite, allez sur Terminal en haut et cliquez sur New Terminal.
Changez le dossier courant pour aller dans le dossier back.
Ensuite, retournez sur Gitlab pour voir les commandes afin d'initier le répertoire Git de back.
Une fois fini, changer le dossier avec votre terminal pour vous rendre dans le dossier front et suivez les instructions pour le répertoire front.
Maintenant, il reste le dossier global qui est plus complexe.
Déplacez votre terminal au bon endroit et faites uniquement la première commande suggérée par Gitlab:
git init --initial-branch=main --object-format=sha1
Avant de faire tout autre chose, nous devons indiquer à Git que back et front ne sont pas des simples dossiers.
En effet, ils ont été initialisés et ils ont leur propre répertoire !
Nous allons donc indiquer à Git que back et front sont des sous-modules !
Exécutez la première commande (que vous devrez adapter):
git submodule add git@gitlab.com:devops9734207/back.git back
Vous devez changer la partie git@gitlab.com:devops9734207/back.git qui correspond à l'adresse de mon répertoire et pas du vôtre ! Pour trouver l'adresse de votre répertoire, il vous suffit de copier celui fourni ici:
Faites de même pour le front:
git submodule add git@gitlab.com:devops9734207/front.git front
Ensuite, nous pouvons reprendre la suite des instructions du répertoire global (git remote, etc...).
Normalement, tout est mis en place.
Vous aurez des erreurs au niveau des pipelines, car les fichiers .gitlab-ci.yml ne sont pas complétés.
Avant de commencer votre mission, nous allons voir les consignes précises.
Consignes
Nous voulons:
- Back:
- Nous voulons que les tests unitaires se lancent ainsi que le linter (voir labos précédents)
- Si le linter échoue, cela ne doit pas faire échouer le pipeline
- Déterminez quels jobs sont interruptibles
- Front:
- Si le linter échoue, cela ne doit pas faire échouer le pipeline
- Déterminez quels jobs sont interruptibles
- Global:
- On veut un premier trigger pour le back et qui dépendra du résultat du pipeline downstream
- Ce premier trigger s'enclenchera dès qu'il y aura un changement dans le dossier
back - On veut un deuxième pipeline pour le front et qui ne dépendra pas du résultat du pipeline downstream (il s'agit d'un linter, on ne souhaite pas bloquer une mise en production)
- Ce deuxième trigger s'enclenchera dès qu'il y aura un changement dans le dossier
front - On veut récupérer les captures d'écran en cas de problème (vous devrez donc utiliser les artifacts).
- Déterminez quels jobs sont interruptibles
Vous remarquerez qu'un fichier .gitlab-ci.yml comporte cette instruction: chmod a=rwx screenshots.
En fait, le container testcafe (qui exécute les tests end-to-end) va prendre automatique des captures d'écran en cas d'échec.
Pour que notre job puisse récupérer ces fichiers, nous faisons un volume partagé.
Cependant, l'utilisateur dans le job et celui dans le container ne sont pas les mêmes et nous avons donc un problème d'accès en écriture.
Cette instruction permet de donner toutes les autorisations à tout le monde.
Ainsi, notre container pourra enfin écrire ses images dans le dossier !
Je vous conseille fortement de commencer à compléter le fichier .gitlab-ci.yml du dossier back, puis front.
S'ils ne sont pas bons, vous n'arriverez pas à faire celui du global sans rencontrer des erreurs.
Pour vous aider:
Voici la liste des mots clés dont vous aurez besoin:
- variables
- GIT_SUBMODULE_STRATEGY
- GIT_SUBMODULE_FORCE_HTTPS
- interruptible
- trigger
- rules
- needs (syntaxe complète)
- artifacts (syntaxe complète)
A vous d'aller voir la documentation pour voir comment ils fonctionnent !
Conclusion
Votre état après le laboratoire
Dans ce laboratoire, nous avons vu comment utiliser le cache et surtout comment nous pouvions travailler avec des pipelines sur plusieurs projets. D'habitude, nous faisons toujours un petit exercice "bonus" pour compléter le laboratoire. Cependant, nous allons utiliser ce bonus pour le laboratoire 5 ! Vous l'aurez peut-être remarqué, mais nos tests end-to-end forcent la reconstruction des images à chaque fois... Dans le projet laboratoire, nous allons remédier à ce problème en utilisant le registry fourni par Gitlab !